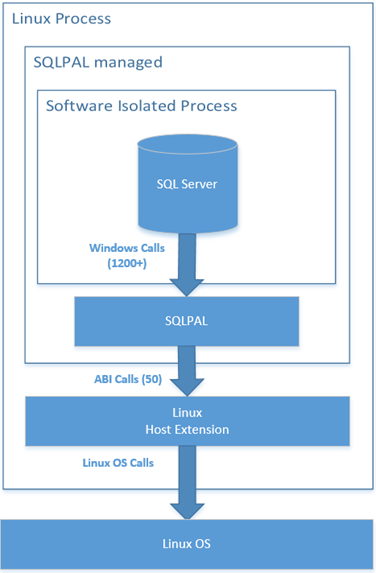
Traditionally, SQL Server is a Windows-based relational database engine. Microsoft introduced SQL Server 2017 in both Windows and Linux platforms. The question is how they compare.
This blogpost will walk through the differences. Let’s begin our journey into SQL Server on Linux.
Note: This blogpost focuses on SQL Server 2019 version for comparisons on both Linux and Windows SQL.
Supported platforms for SQL Server on Linux are the following:
- Red Hat Enterprise Linux 7.7 – 7.9, or 8.0 – 8.3 Server
- SUSE Enterprise Linux Server v12 SP3 – SP5
- Ubuntu 16.04 LTS, 18.04 LTS, 20.04 LTS
- Docker Engine 1.8+ on Windows, Mac, or Linux
What are the system requirements for SQL Server on Linux?
SQL Server has the following minimum requirements for SQL Server for Linux:
- Processors: x-64 compatible
- Memory: 2 GB
- Number of cores: 2 cores
- Processor speed: 2 GHz
- Disk space: 6 GB
- File system: XFS or EXT4
- Network File System (NFS): NFS version 4.2 or higher
Note: You can only mount the /var/opt/mssql directory on the NFS mount.
What are the supported editions of SQL Server on Linux?
In this section, we talk about different editions of SQL Server on Linux, and their use-cases. These editions are similar to the SQL Server on Windows environment.
| Enterprise | The Enterprise edition is Microsoft’s premium offering for relational databases. It offers all high-end data center capabilities for mission-critical workloads along with high availability and disaster recovery solutions. |
| Standard | The Standard edition has an essential data management and business intelligence database. |
| Developer | The Developer Edition has all features of the enterprise edition. It cannot be used in production systems. However, it can be used for development and test environments. |
| Web | The Web edition is a low-cost database system for Web hosting and Web VAPs. |
| Express edition | The Express edition is a free database for learning and building small data-driven applications. It is suitable for software vendors, developers. |
Editions of SQL Server on Linux and Windows
The editions specified below apply to both Windows SQL Server and Linux:
| Feature | Express | Web | Standard | Developer | Enterprise |
|---|---|---|---|---|---|
| Maximum relational database size | 10 GB | 524 PB | 524 PB | 524 PB | 524 PB |
| Maximum memory | 1410 MB | 64 GB | 128 GB | Operating System Maximum | Operating System Maximum |
| Maximum compute capacity – DB engine | 1 socket or 4 cores | 4 sockets or 24 cores | 4 sockets or 24 cores | Operating system maximum | Operating system maximum |
| Maximum compute capacity – Analysis or Reporting service | 1 socket or 4 cores | 4 sockets or 24 cores | 4 sockets or 24 cores | Operating system maximum | Operating system maximum |
| Log shipping | NA | Supported | Yes | Yes | Yes |
| Backup compression | NA | NA | Yes | Yes | Yes |
| Always On failover cluster instance | NA | NA | Yes | Yes | Yes |
| Always On availability groups | NA | NA | NA | Yes | Yes |
| Basic availability group | NA | NA | Yes | NA | NA |
| Clusterless availability group | NA | NA | Yes | Yes | Yes |
| Online indexing | NA | NA | NA | Yes | Yes |
| Hot add memory and CPU | NA | NA | NA | Yes | Yes |
| Backup encryption | NA | NA | NA | Yes | Yes |
| Partitioning | Yes | Yes | Yes | Yes | Yes |
| In-Memory OLTP | Yes | Yes | Yes | Yes | Yes |
| Always Encrypted | Yes | Yes | Yes | Yes | Yes |
| Dedicated admin connection | Yes, it requires a trace flag | Yes | Yes | Yes | Yes |
| Performance data collector | NA | Yes | Yes | Yes | Yes |
| Query Store | Yes | Yes | Yes | Yes | Yes |
| Internationalization support | Yes | Yes | Yes | Yes | Yes |
| Full-text and semantic search | Yes | Yes | Yes | Yes | Yes |
| Integration Services | Yes | NA | Yes | Yes | Yes |
Note: You can refer to Microsoft documentation for detailed features details and comparison.
Features not supported by SQL Server on Linux
The following SQL Server features are not supported on Linux.
- Is there any difference in the SQL Server licensing on Linux and Windows?
There is no difference in the licensing for Windows and SQL Server Linux. You can use the licenses on the cross-platforms. For example, if you have a Windows-based license, you can use it for Linux SQL Server.
| Database Engine features | Merge replication Distributed query with 3rd-party connections File table, FILESTREAM Buffer Pool Extension Backup to URL (page blobs) |
| SQL Server Agent | Alerts Managed backups CmdExec, PowerShell, Queue Reader, SSIS, SSAS, SSRS |
| Services | SQL Server Browser Analysis service Reporting service R services Data Quality Services Master data service |
| Security | AD Authentication for Linked Servers AD Authentication for Availability Group (AG) Endpoints Extensible Key Management (EKM) |
- Can you use SQL Server Management Studio for connecting with SQL Server on Linux?
Yes, we can use it. However, the SQL Server Management Studio ( SSMS) can be installed on a Windows server and remotely access the Linux SQL Server.
- Do we require a specific version of SQL Server to move from SQL Server Windows to Linux?
No, you can move your existing databases in any version of SQL Server from Windows to Linux.
- Can we migrate databases from Oracle or other database engines to SQL Server on Linux?
Yes, you can use SQL Server Migration Assistant (SSMA) for migrating from Microsoft Access, MySQL, DB2, Oracle or SAP ASE to SQL Server on Linux.
- Can we install SQL Server for Linux on Linux Subsystem for Windows 10?
No, Linux Subsystem for Windows 10 is not supported.
- Can we perform an unattended installation of SQL Server on Linux?
Yes.
- Is there any tool to install on Linux SQL Server for connection or executing queries?
Yes, you can install Azure Data Studio on Linux as well. It is a cross-database platform tool with rich features for development, such as below.
- Code editor with IntelliSense
- Code snippets
- Customizable Server and Database Dashboards
- Integrated Terminal for Bash, PowerShell, sqlcmd, BCP, and ssh
- Extensions for additional features
You can refer to Microsoft documentation for more details on Azure Data Studio.
- Do we have a utility like SQL Server Configuration Manager for Linux?
SQL Server Configuration Manager lists down SQL Services, their status, network protocols, ports, file system configurations in a graphical window for Windows.
SQL Server Linux includes a command-line utility mssql-conf for these configurations.
- Can we use Active Directory Authentication for SQL Server on Linux?
Yes, you can configure and use AD credentials to connect SQL Server on Linux with AD authentications.
- Can we configure the replication from Windows to Linux or vice versa?
Yes, you can use read scale replicas for one-way data replication between Windows to Linux SQL or vice versa.
Conclusion
It is essential to know the SQL Server on Linux edition, features and how it is different from SQL Server running on Windows. Therefore, this article provided a comparison between SQL Server on Windows and Linux operating systems. You should understand the differences and evaluate your requirements while planning to move your databases to SQL Server on Linux.
OK, folks that’s it for this post. Have a nice day guys…… Stay tuned…..!!!!!
Don’t forget to like & share this post on social networks!!! I will keep on updating this blog. Please do follow!!!